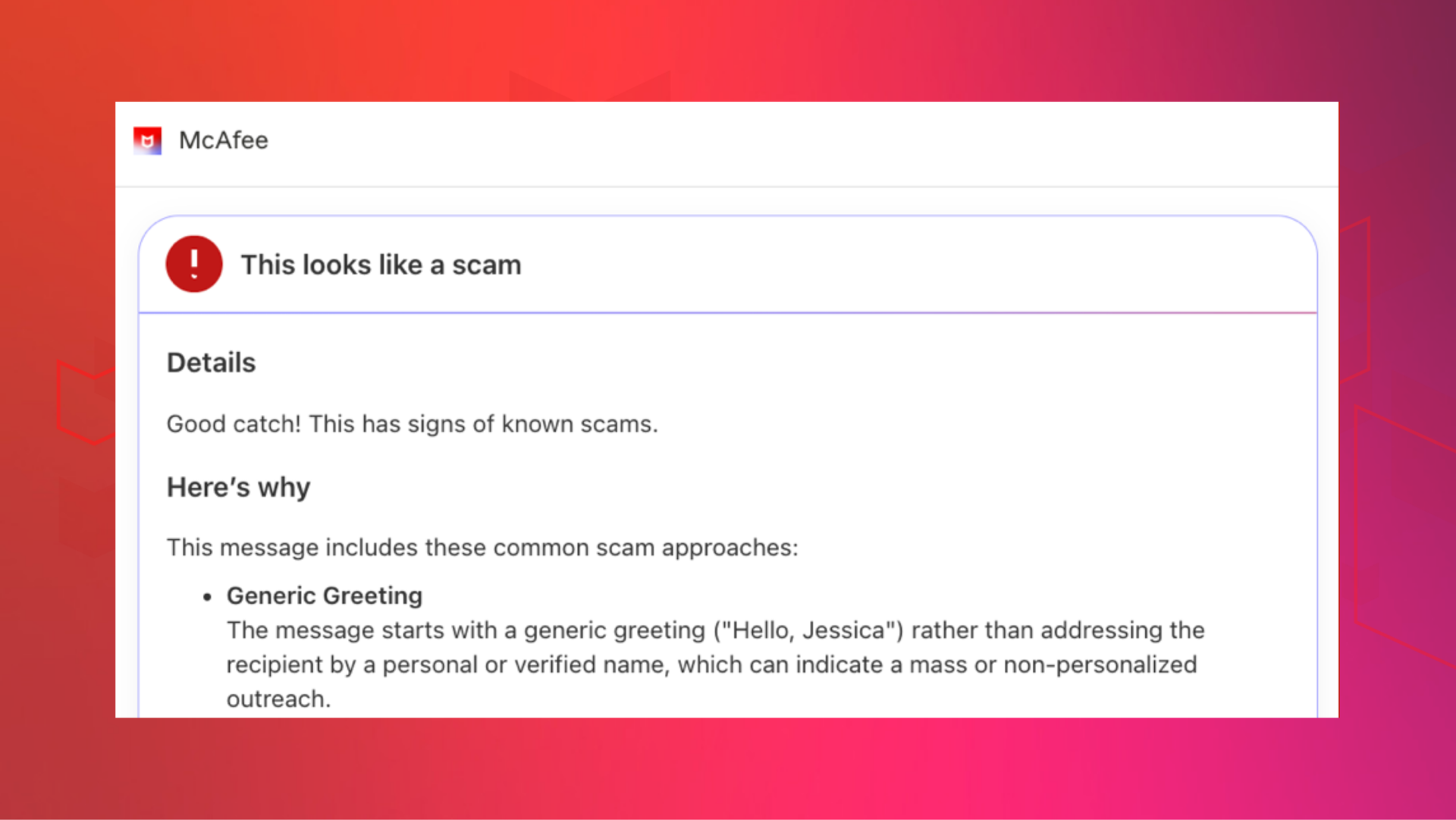
How to Use Claude with McAfee to Check “Is This a Scam?”
Jul 20, 2026 | 5 MIN READ
How to Use Claude with McAfee to Check “Is This a Scam?”
Use Claude with McAfee to check suspicious links, messages, and screenshots in seconds. Learn how this new integration helps you...Jul 20, 2026 | 5 MIN READ

How to Know If Your Phone Has Been Hacked
It’s often pretty easy to tell when a piece of your tech isn’t working quite right. The...Jul 07, 2026 | 15 MIN READ

Is That Delivery Text Real? How to Spot Package Smishing and Delivery Scams
Fake delivery texts from USPS, UPS, FedEx, DHL, and Amazon are among the most common scams today. Learn how package...Jun 23, 2026 | 4 MIN READ

Chick-fil-A Data Breach Explained: What Customers Need to Know
Hackers targeted Chick-fil-A loyalty accounts in a credential stuffing hack using stolen usernames and passwords. Learn what happened and how...Jul 24, 2026 | 3 MIN READ
How to Use Claude with McAfee to Check “Is This a Scam?”
Use Claude with McAfee to check suspicious links, messages, and screenshots in seconds. Learn how this new integration helps you...Jul 20, 2026 | 5 MIN READ

The FaceTime Bank Scam That Can Expose Your Passwords in Real Time: This Week in Scams
Scammers don’t always need sophisticated malware to steal your money. Increasingly, they’re relying on something much simpler: your trust. This week, fraudsters...Jul 17, 2026 | 4 MIN READ
How to Use Claude with McAfee to Check “Is This a Scam?”
Use Claude with McAfee to check suspicious links, messages, and screenshots in seconds. Learn how this new integration helps you...Jul 20, 2026 | 5 MIN READ
The FaceTime Bank Scam That Can Expose Your Passwords in Real Time: This Week in Scams
Scammers don’t always need sophisticated malware to steal your money. Increasingly, they’re relying on something much simpler: your trust. This week, fraudsters...Jul 17, 2026 | 4 MIN READ

Nearly 7 Million Driver’s Licenses Exposed in Assurance Breach: This Week in Scams
An insurance data breach exposed nearly 7 million driver's license numbers, while fake Robinhood investment texts continue stealing thousands from...Jul 09, 2026 | 5 MIN READ
Chick-fil-A Data Breach Explained: What Customers Need to Know
Hackers targeted Chick-fil-A loyalty accounts in a credential stuffing hack using stolen usernames and passwords. Learn what happened and how...Jul 24, 2026 | 3 MIN READ
How to Use Claude with McAfee to Check “Is This a Scam?”
Use Claude with McAfee to check suspicious links, messages, and screenshots in seconds. Learn how this new integration helps you...Jul 20, 2026 | 5 MIN READ
The FaceTime Bank Scam That Can Expose Your Passwords in Real Time: This Week in Scams
Scammers don’t always need sophisticated malware to steal your money. Increasingly, they’re relying on something much simpler: your trust. This week, fraudsters...Jul 17, 2026 | 4 MIN READ
Chick-fil-A Data Breach Explained: What Customers Need to Know
Hackers targeted Chick-fil-A loyalty accounts in a credential stuffing hack using stolen usernames and passwords. Learn what happened and how...Jul 24, 2026 | 3 MIN READ
How to Use Claude with McAfee to Check “Is This a Scam?”
Use Claude with McAfee to check suspicious links, messages, and screenshots in seconds. Learn how this new integration helps you...Jul 20, 2026 | 5 MIN READ
Nearly 7 Million Driver’s Licenses Exposed in Assurance Breach: This Week in Scams
An insurance data breach exposed nearly 7 million driver's license numbers, while fake Robinhood investment texts continue stealing thousands from...Jul 09, 2026 | 5 MIN READ
Chick-fil-A Data Breach Explained: What Customers Need to Know
Hackers targeted Chick-fil-A loyalty accounts in a credential stuffing hack using stolen usernames and passwords. Learn what happened and how...Jul 24, 2026 | 3 MIN READ
How to Use Claude with McAfee to Check “Is This a Scam?”
Use Claude with McAfee to check suspicious links, messages, and screenshots in seconds. Learn how this new integration helps you...Jul 20, 2026 | 5 MIN READ
The FaceTime Bank Scam That Can Expose Your Passwords in Real Time: This Week in Scams
Scammers don’t always need sophisticated malware to steal your money. Increasingly, they’re relying on something much simpler: your trust. This week, fraudsters...Jul 17, 2026 | 4 MIN READ

Take control with McAfee+ Advanced
Full-service identity and credit protection now in one plan
Get McAfee+ Advanced